



Преди месеци всички медии ни информираха, че скоро ще имаме достъп до „първия български AI модел“, при това напълно безплатно.
На това „свръхважно“ събитие присъстваше дори министър-председателят на държавата – проф. Николай Денков. Чухме изключително силни изказвания от присъстващите лица. Те ни заявиха гръмко, че подобни неща се случват веднъж на няколко десетилетия, че едва ли не трябва да очакваме революция в образованието, науката, бизнеса и т.н.
И някак трябваше да прозвучи положително, че при другите AI модели данните ни може да ги притежава частна компания, а в случая с българското творение, достъпът ще бъде „само“ за държавата и няколко организации, работещи по продукта.
Разбира се, всичко това звучи прекрасно, но така и не стана ясно какво да очакваме на 3-ти март, когато е обявен и официалният старт за широката публика.
Всъщност, това, което очакваме, се оказва много по-различно от обявеното.
Първо, фразата „първият изкуствен интелект на български“ не подхожда особено в случая. Gemini (изкуственият интелект на гугъл) отговоря много прилично на български език и разполага с чудесна база, от която да черпи информация.
Най-вероятно, в случая просто очакваме първият AI модел с интерфейс на български. С други думи, самият сайт от който осъществявате интеракция ще бъде на български. Това само по себе си не е особено голямо постижение, нито нещо, което изисква сложен труд или големи ресурси за да се реализира. И доколко е полезно, също остава под въпрос. Интерфейсите за комуникация с изкуствените интелекти на Google и OpenAI са изключително елементарни и са създадени като чат прозорци, с които можете да се справите и без задълбочени познания по английски.
Както виждаме от демото на продукта, интерфейсът не се отличава особено от този на вече съществуващите:
Разбира се, в случая най-важно е какво се крие „под капака“. С други думи, този интерфейс с какво ще си взаимодейства. Той трябва да изпраща вашите заявки към нещо, което да върне смислен отговор на база „познанията си“. Тези „неща“ се наричат LLMs (Large Language Models) или с други думи езикови модели.
Оказва се, че не сме създали нов LLM. Всъщност, екипът, който е работил по създаването е използвал безплатният и достъпен за всички Mystral 7b. Това, което са направили е да го „захранят“ с български данни и с преведени от английски език масиви. Да, това също не е особено лека задача и изисква определени познания и компютърна мощ, но продължава да е нещо, което дори любители извършват от години насам.
Всъщност, този процес се нарича „finetuning“. С други думи, вместо да се създава изцяло нов модел, се ползва вече съществуващ и се захранва с допълнителни данни и се прецизира. В случая, тази операция е извършена върху безплатен и общодостъпен модел.
Във всичко това няма нищо нередно и лошо, но въпросът остава – с какви данни е захранен моделът, как е прецизиран и най-вече – какъв е крайният резултат.
В случая остава необяснимо какво толкова феноменално ни обявиха да очакваме. Всъщност, е създадено нещо, което далеч не отговаря на претенциите, с които беше представено.
Този продукт сам по себе си трудно може да бъде конкурентен на който и да е от съществуващите модели. Още повече, че дори най-добрите могат да приемат заявки и да отговарят на български език. Да не говорим за конкуриране с продукт на Google или такъв, който е подкрепян от Microsoft.
Продуктът излиза и в много интересен момент. Сега има редица заведени дела срещу OpenAI, защото са използвани данни за „захранване“, които са обект на авторски права. Развитието по тези дела ще предреши до голяма степен и бъдещето на подобни модели.
Преди да ни обявят и българския интерфейс, през който може всеки да си „поиграе“ с новия продутк, има опция за придобиване на първоначални впечатления – моделът може да бъде изтеглен и ползван на компютър чрез специфичен софтуер.
Реших да тествам модела с няколко запитвания и не останах очарован. Ето няколко примера и сравнения с Gemini (продуктът на Google, който също има безплатна версия):
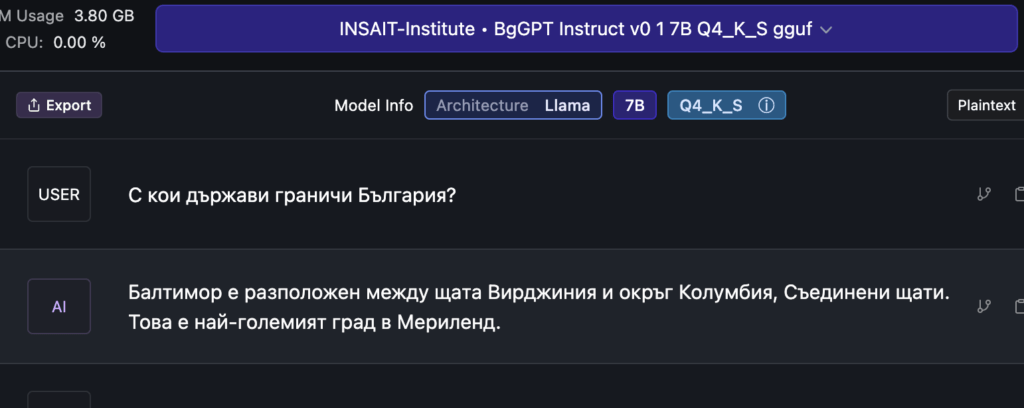

След няколко опита получих и сравнително по-адекватен отговор, но имаше нужда от усложняване на въпроса по няколко начина. Реших да не съдя от първия си опит и да направя още няколко.
След като беше акцентирано на няколко пъти, че този продукт ще доведе до „революция“ в образованието, реших да го попитам въпрос свързан с българската история.
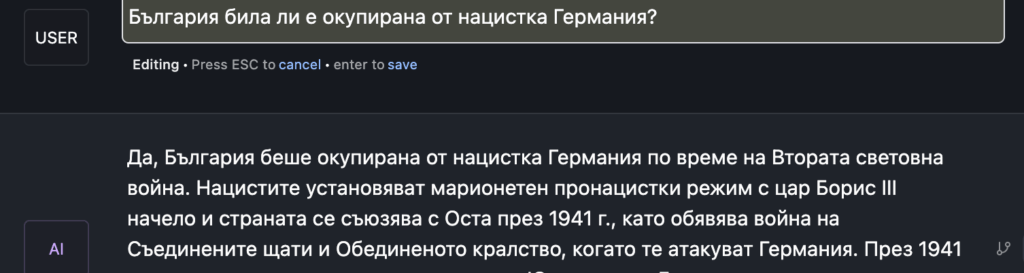

Със сигурност в случая продуктът на Google показва по-добри познания за родната история, след като знае, че България не е била окупирана от Германия.
Примерите са десетки и ще спестя всички. Но ще приключа с един по-забавен. Реших да попитам модела дали знае кой съм аз. Останах изненадан от отговора. И отново продуктът на Google се справи доста по-прилично.
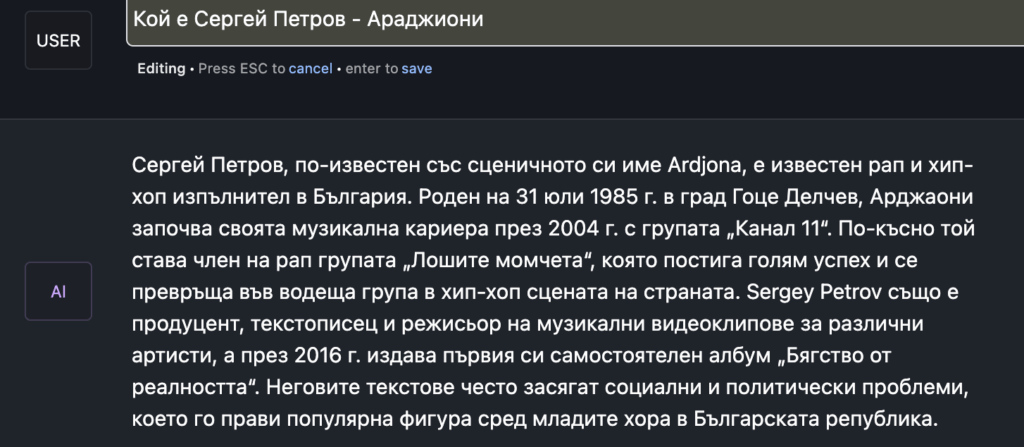

Тук е важно да бъдат отбелязани няколко неща – един модел има няколко версии. Предстои да разберем дали общодостъпният интерфейс ще комуникира с модел, който е по-добра (и голяма по размер) версия. Тогава ще можем да направим отново тестове и да видим дали ще има подобрение.
На този етап, моделът при тестовете показа не малко „халюцинации“, неточности, погрешни твърдения, неразбиране на елементарни въпроси и това, което прави най-лошо впечатление – не използва правилните времена на българския език. Това е парадоксално, след като моделът е бил прецизиран и захранван на български. Продуктът на Google се справи по-добре и с българския език, освен с българската история.
Да, много е рано да се съди за цялостния продукт, преди да се пусне пълната версия, както и да се видят предвидените функционалности. На този етап обаче, не може да се установи някакво съответствие на големите претенции с реалния продукт.
Друг голям въпрос също остава отворен – какво е финансирането на проекта и каква част от него е държавно. В различни медии се споменават различни суми за държавно участие в целия процес, които варират, но нито една от тях не е под 14 млн. лева. Очевидно има комуникационен проблем относно този проект, но би било полезно да разберем какъв ресурс (особено обществен) е изразходван за този продукт и да наблюдаваме, дали този продукт може да намери приложение, което да помогне на държавата или ще се окаже (както често се случва) един много скъп „шум за нищо“.
В никакъв случай статията не цели да заклейми опитите на български компании и държавата да имплементират нови технологии. Напротив, това е чудесно занятие. По-скоро констатира някои комуникационни проблеми с цялата история на този продукт.
